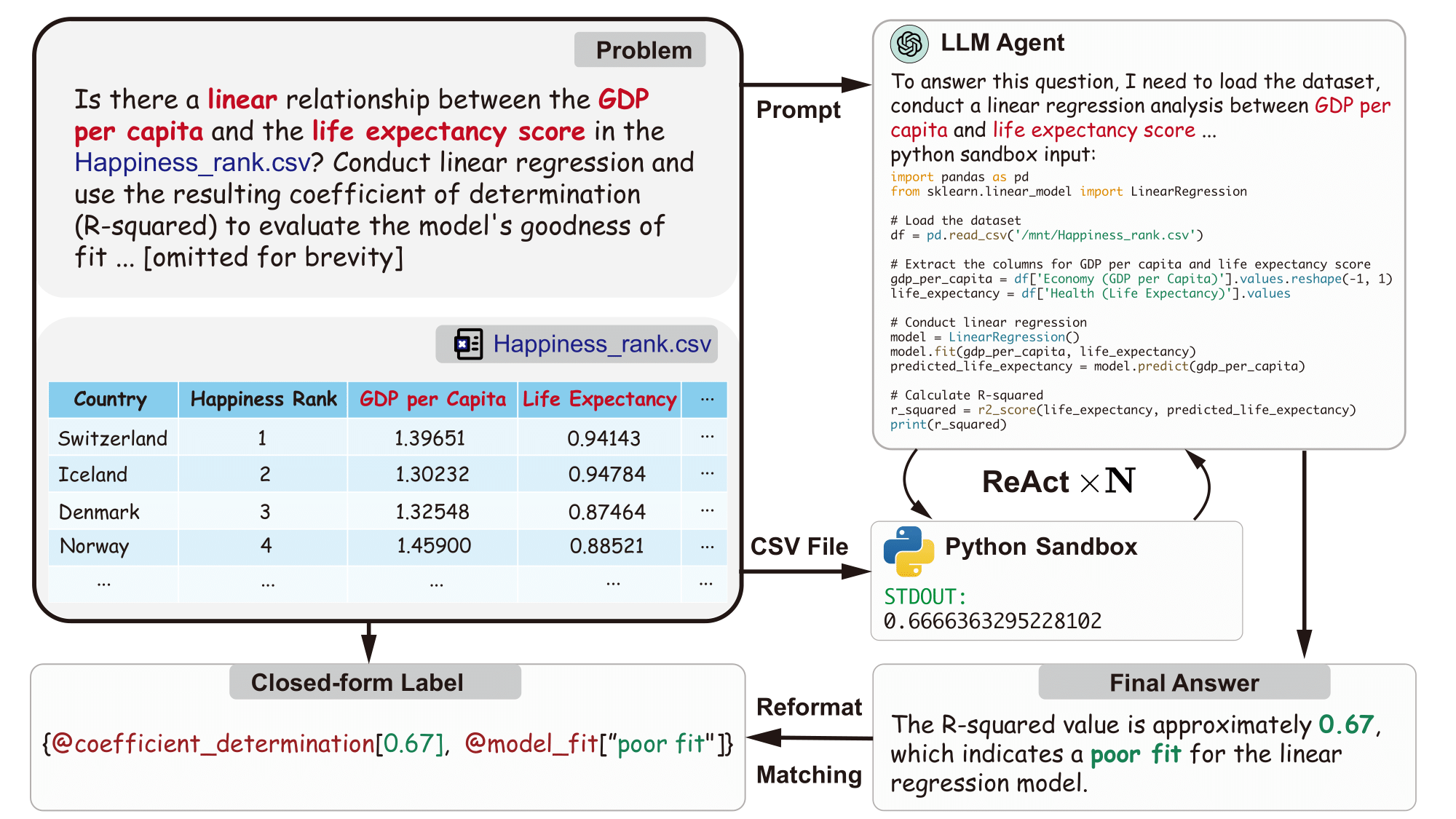
In this section, we furnish a comprehensive evaluation of both close-source LLMs such as GPT-4 and GPT-3.5, as well as widely-utilized open-source LLMs. In addition, we test our DAAgent, which is an agent for data analysis with instruction-tuning.
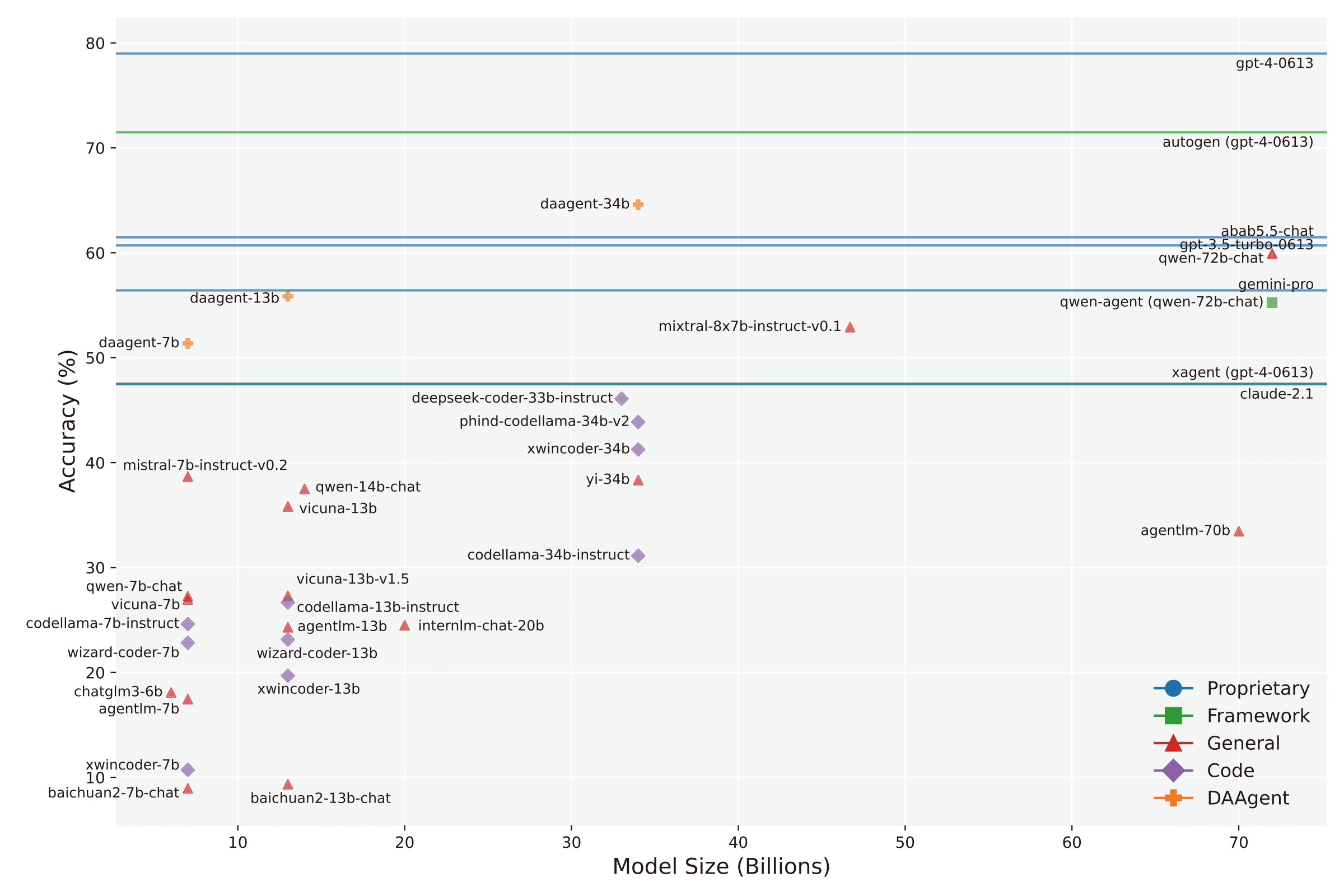
| Rank | Model Name | # Params. (in B) | Proportional Accuracy by Subquestions | Accuracy by Questions | Uniform Accuracy by Subquestions | |
|---|---|---|---|---|---|---|
| 1 | gpt-4-0613 | / | 74.60% | 78.72% | 79.01% | |
| 2 | daagent-34b | 34 | 60.77% | 67.50% | 62.98% | |
| 3 | abab5.5-chat | / | 60.13% | 65.94% | 64.27% | |
| 4 | gpt-3.5-turbo-0613 | / | 58.20% | 65.70% | 61.88% | |
| 5 | qwen-72b-chat | 72 | 57.56% | 62.46% | 56.17% | |
| 6 | daagent-13b | 13 | 54.52% | 60.51% | 55.72% | |
| 7 | gemini-pro | / | 53.38% | 58.32% | 51.93% | |
| 8 | mixtral-8x7b-instruct-v0.1 | 46.7(12.9) | 49.20% | 54.02% | 51.38% | |
| 9 | daagent-7b | 7 | 49.02% | 57.63% | 54.19% | |
| 10 | deepseek-coder-33b-instruct | 33 | 44.84% | 48.90% | 46.31% | |
| 11 | claude-2.1 | / | 43.41% | 49.65% | 46.96% | |
| 12 | phind-codellama-34b-v2 | 34 | 42.02% | 47.41% | 44.40% | |
| 13 | xwincoder-34b | 34 | 39.87% | 45.46% | 42.73% | |
| 14 | mistral-7b-instruct-v0.2 | 7 | 36.45% | 41.61% | 36.90% | |
| 15 | qwen-14b-chat | 14 | 36.45% | 41.36% | 34.51% | |
| 16 | qwen-7b-chat | 7 | 27.27% | 27.27% | 16.00% | |
| 17 | vicuna-13b-v1.5 | 13 | 26.26% | 30.88% | 26.31% | |
| 17 | internlm-chat-20b | 20 | 23.79% | 26.82% | 25.05% | |
| 17 | wizardcoder-python-34b-v1.0 | 34 | 23.13% | 26.45% | 22.40% | |
| 18 | agentlm-7b | 7 | 16.99% | 20.71% | 17.89% | |
| 19 | chatglm3-6b | 6 | 16.67% | 20.59% | 19.27% | |
| 20 | codellama-34b-instruct | 34 | 14.56% | 17.39% | 13.94% |
The advent of Large Language Models (LLMs) has spurred the development of LLM-augmented Autonomous Agents (LAAs). These agents are capable of generating and executing code through ongoing interactions between their core LLM and the code execution environment. In this project, we introduce InfiAgent-DABench, the first benchmark specifically designed to evaluate LLM-based agents in data analysis tasks. This benchmark contains DAEval, a dataset consisting of data analysis questions derived from CSV files, and an agent framework to evaluate LLMs as data analysis agents. This page describes the details of InfiAgent-DABench framework, including features such as dataset construction, evaluation metrics, analytical assessment, and the procedural details about pipeline onboarding.
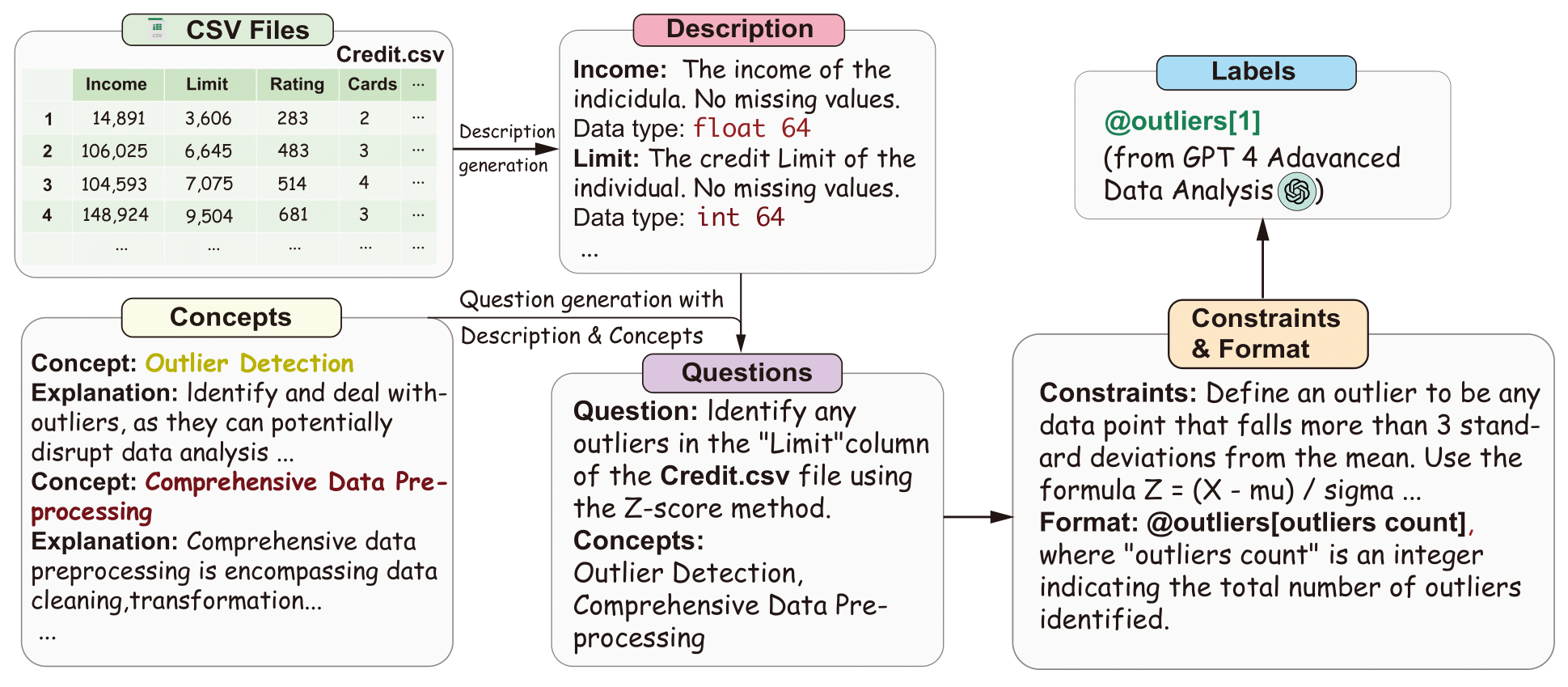 We split the dataset into a validation set and a test set. The validation dataset contains 311 questions with 55 csv files. We only public the validation set to avoid data leakage. Here're some examples:
We split the dataset into a validation set and a test set. The validation dataset contains 311 questions with 55 csv files. We only public the validation set to avoid data leakage. Here're some examples:
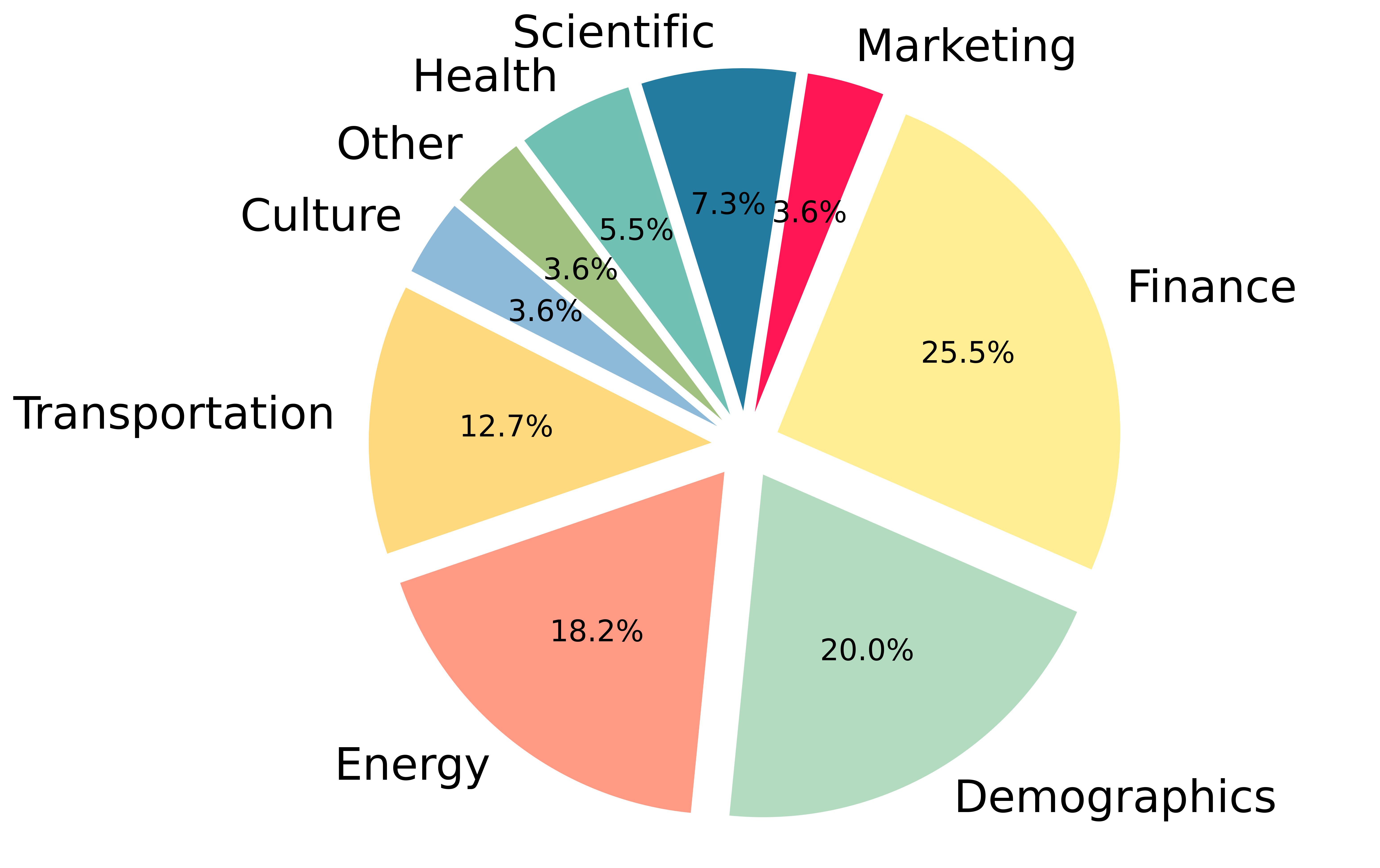
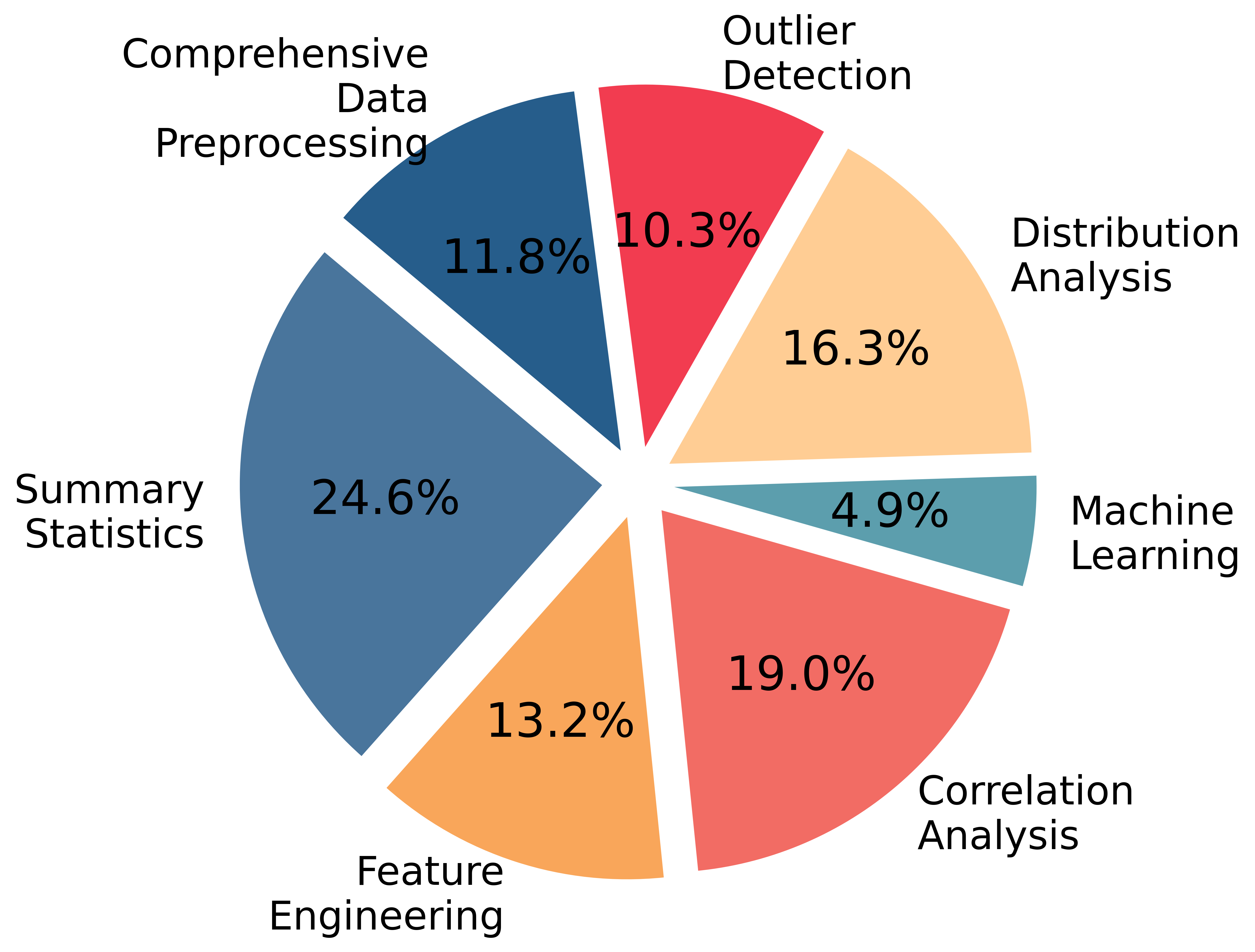
 We categorize CSV files within the dataset into nine distinct categories, determined by their respective domains:
We categorize CSV files within the dataset into nine distinct categories, determined by their respective domains:
Below is the pie chart depicting the categorical distribution:
We conduct statistical analyses on the individual concepts associated with each question, accounting for scenarios where a question encompasses multiple concepts:
For closed-form questions, we prompt LLMs with question description. Considering that most models hardly follow the format requirements, we add a reformat step for all models by using gpt-3.5-turbo-16k to format the responses given the format requirements. Here's a figure illustrating this process:

conda create -n agent python==3.9.12
pip3 install -r requirements.txtdocker build -t myimg .# initialize poetry
poetry init
# Supported LLM: OPEN_AI, AZURE_OPEN_AI
# api_key is required for API-based models
bash run_demo.sh --llm AZURE_OPEN_AI --api_key 123
# Take llama-2-7b as an example
python3 src/activities/vllm_api_server.py --model "meta-llama/Llama-2-7b-hf" --served_model_name "meta-llama/Llama-2-7b-hf"At this point, we only support Linux environment.
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Llama-2-7b-hf",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'bash run_demo.sh --llm "meta-llama/Llama-2-7b-hf"Our demo is designed to default to the use of the front-end. If you prefer not to use the front-end and instead perform command-line operations or process large amounts of data, you can refer to the following commands:
# Run with API.
python3 ./src/activities/eval.py --llm AZURE_OPEN_AI --api_key 123
# Run with local model.Take llama-2-7b as an example.
python3 ./src/activities/eval.py --llm "meta-llama/Llama-2-7b-hf"@misc{hu2024infiagentdabench,
title={InfiAgent-DABench: Evaluating Agents on Data Analysis Tasks},
author={Xueyu Hu and Ziyu Zhao and Shuang Wei and Ziwei Chai and Guoyin Wang and Xuwu Wang and Jing Su and Jingjing Xu and Ming Zhu and Yao Cheng and Jianbo Yuan and Kun Kuang and Yang Yang and Hongxia Yang and Fei Wu},
year={2024},
eprint={2401.05507},
archivePrefix={arXiv},
primaryClass={cs.CL}
}